k-meansの使い方
k-meansの説明
Gofardはk-mean法によるクラスタリング(データ分類)を行えます。
k-mean法は初めに分類したい数(クラスター数)を指定し、それに応じて似た特徴をもつデータサンプルごとに分類することができます。
データの特徴を探したり、分割回帰に利用されたりなど、様々な目的に利用される手法です。
k-meansの分析例
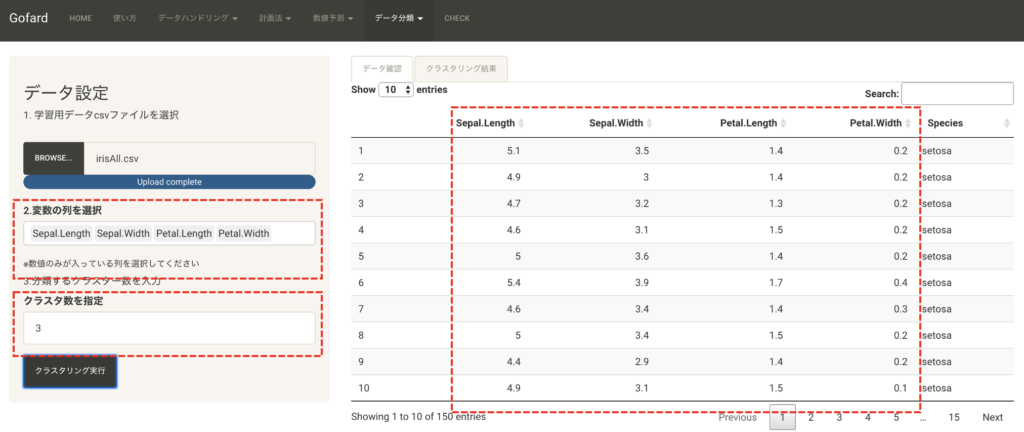
アヤメ(iris)の3品種分類データに対してクラスタリング例を示します。
このデータは3品種のアヤメ『setosa』、『versicolor』、『virginica』を各50サンプルずつ”がく片 (Sepal)”と”花弁 (Petal)” を幅および長さの4つの計測値でまとめたデータセットです。
k-meansでは数値が入っている変数列を選択し、クラスター数を指定(この例では3)し、 クラスタリングを実行すれば結果タブにグラフとクラスター番号が結合されたデータリストを出力します。
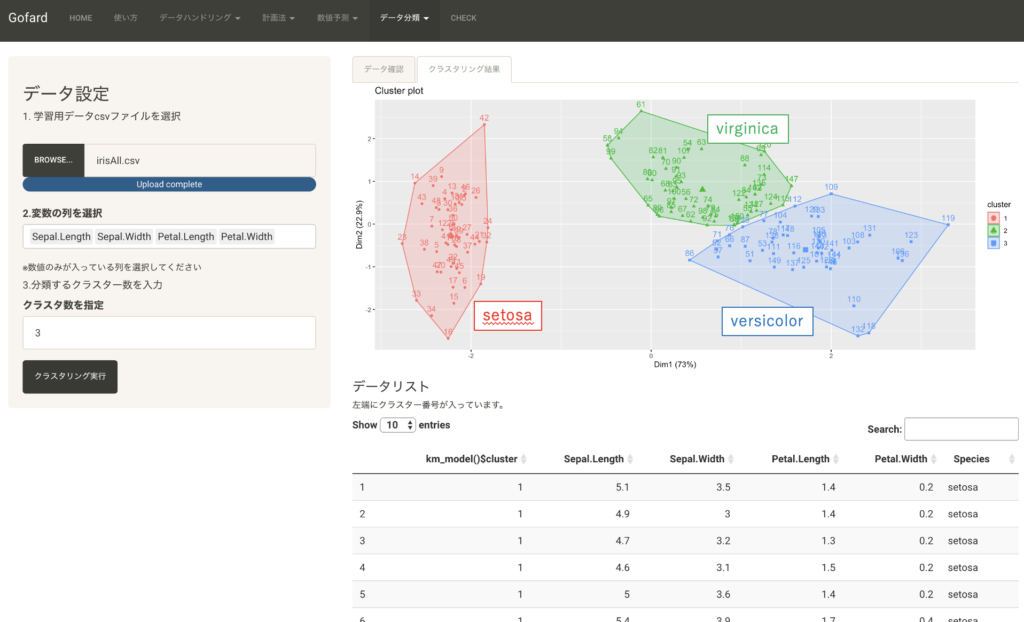
誤分類もあるが、ほとんど3品種ごとにクラスター分けされていることがデータリストから確認出来る。このようにk-meansは似た特徴のデータサンプルごとに分類が出来ます。
結果データリストはcsvファイルとしてページ下部からダウンロードできます。

結果したcsvデータを「散布図」や「棒グラフ・箱ヒゲ図」でどのような分類がされたか良く観察できるので、オススメです。
k-meansの注意点
このアルゴリズムはクラスターの初期中心点をランダムに決定する為、計算毎に異なる結果を出すことがあります。irisデータも下図のような実行結果になる場合があります。
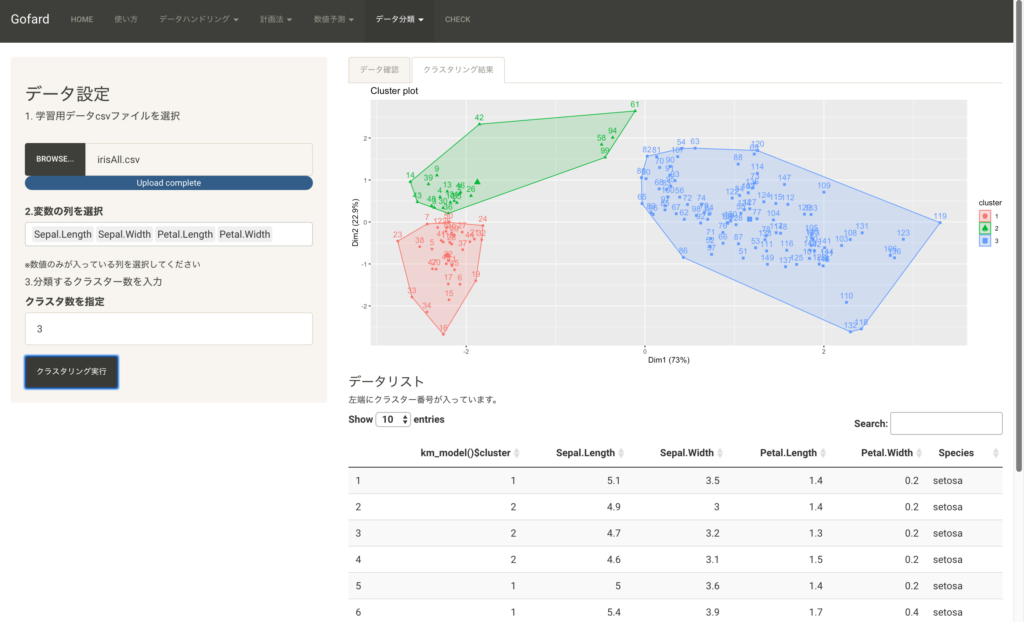
その為、k-meansは複数回実行し、データと目的に応じて解釈しやすい結果を選択してください。

